

该服务是一款OpenVINO™容器化部署工具,灵活且高效,兼容Tensorflow Serving API,支持gRPC和RESTfull API接口,整个架构如下图所示:
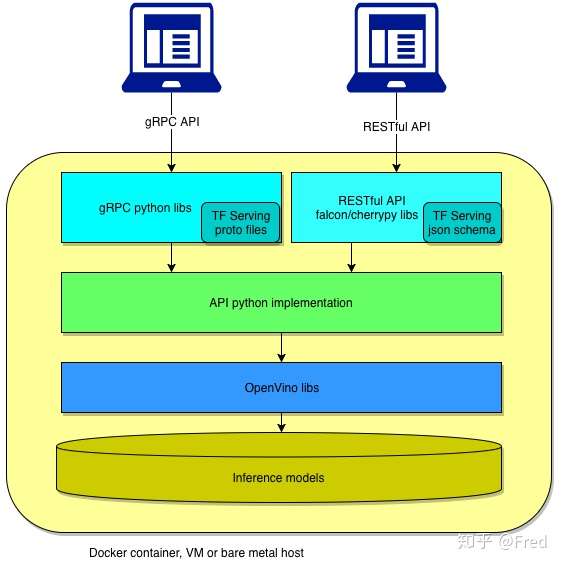
如果曾经或用过OpenVINO来做加速,那么转到容器化部署上只需要几分钟时间,如果第一次接触OpenVINO,那么建议优先使用OpenVINO-Model-Server。
如果你在Tensorflow Serving上做推理,迁移过来比上面的多一个模型转换,一条离线命令而已。
为什么这么说呢?
OpenVINO开发一般分为两部分:Model转换优化和调用API做Inference。
调用API做inference除了需要coding之外,还要根据CPU类型进行配置优化,如果线上硬件和资源不一样,又要重新配置参数。而这些过程在OpenVINO-Model-Server看来是不需要的,如果你要快速使用OpenVINO搭建一个服务,那么OpenVINO-Model-Server是一个不错的推荐。
当然,好处还不仅如此!
支持模型热更新
支持多模型部署
支持多种硬件CPU/VPU/FPGA
容器化部署
这里只讨论一种容器化部署,docker容器,k8s或裸机部署可以参阅文档
安装依赖包,并拉取镜像
[root@user~]# yum install docker [root@user~]# docker pull intelaipg/openvino-model-server
准备模型
转换模型为IR格式文件,如果模型已经转好IR文件,修改名字为ir_model.*即可,模型组织方式如下:
--model | -- 1 | | | -- ir_model.bin | | | -- ir_model.xml -- 2 | -- ir_model.bin | -- ir_model.xml ...
2. 启动服务
[root@user~]# docker run --rm -d -p 9002:9002 -v /tmp/model:/opt/ml/openvino:ro intelaipg/openvino-model-server /ie-serving-py/start_server.sh \ ie_serving model --model_path /opt/ml/openvino --model_name resnet50 \ --port 9002 --grpc_workers 8 --nireq 4
参数介绍:
--grpc_workers 接收客户端请求并解包的线程数
--nireq 推理线程
两者关系是: nireq的数目介于grpc_workers数目的1倍到2倍之间。
推理线程设置数目可硬件资源相关,核多可以多启几个推理线程。
客户端请求
安装依赖包
[root@user~]# pip install python numpy tensorflow-serving-api [root@user~]# pip install tensorflow==1.15.0
这里以ResNet50为例,client端的脚本如下:
import tensorflow as tfimport cv2from grpc.beta import implementationsfrom tensorflow_serving.apis import predict_pb2from tensorflow_serving.apis import prediction_service_pb2_grpcchannel = implementations.insecure_channel("xx.xx.xx.xx:9002")stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)# create requestrequest=predict_pb2.PredictionRequest()request.model_spec.name='resnet50'request.model_spec.signature_name='serving_default'# prepare dataimage_raw_data=tf.gfile.FastGFile(image, 'rb').read()with tf.Session as sess:
img_data = cv2.imread(image)
resized = cv2.resize(img_data, (224,224))
resized = cv2.cvtColor(resized, cv2.COLOR_BGR2RGB)
tensor = tf.contrib.util.make_tensor_proto(resized.astype(dtype=np.float32), shape=[1] + list(resized.shape))
# fill input
request.inputs['input'].CopyFrom(tensor)
response = stub.Predict(request, 10.0)
result = response.outputs['predict']
print(result)利用这个脚本可以做client端的压测,至于要做多大的batch的测试,多少路测试,请各位看官自行解决。
再多说一句
OpenVINO-Model-Server的推理是异步进行的,适合云端部署场景,edge端一般流程是同步方式,部署起来一般一个模型只有一个infer线程。
这种异步推理方式可以榨干你的CPU等计算资源。
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂