电子产品世界
业界动态
设计应用
牛人业话
暴力拆解
EEPW观点
嵌入式系统
元件/连接器
电源与新能源
安防与国防
汽车电子
EDA/PCB
消费电子
工控自动化
模拟技术
医疗电子
测试测量
手机与无线通信
光电显示
网络与存储
智能计算
物联网与传感器
论坛
在线研讨会
博客
电子设计方案
白皮书
最新推荐
电子新闻
设计应用
牛人业话
暴力拆解
嵌入式系统
元件/连接器
电源与新能源
安防与国防
汽车电子
EDA/PCB
消费电子
工业自动化
模拟技术
医疗电子
测试测量
通信技术
光电显示
网络与存储
智能计算
物联网与传感器
1
2
3
Nexperia再度蝉联博世全球供应商大奖
元件/连接器
2021-08-05
适用于热插拔的Nexperia新款特定应用MOSFET
电源与新能源
2021-08-05
向下一散热世代进发,浸没式液冷主机圆满完成ChinaJoy之旅
消费电子
2021-08-05
5G扬帆深度报道之七:5G筑路数字经济,创新引领有色金属绿色智慧工厂
手机与无线通信
2021-08-05
如何避免视频会议潜在涉密风险?保伦电子itc视频会议如何为会议数据安全加密?
网络与存储
2021-08-05
国货当自强,中国科技助力打赢疫情持久战
医疗电子
2021-08-05
连续4年登《财富》500强,是否反映出海尔智家的真正实力与潜力?
物联网与传感器
2021-08-05
人大金仓荣膺数字化服务领军企业奖
智能计算
2021-08-05
清醒异构牵手知名AI厂商,推动gem5模拟器向工业界迁移
智能计算
2021-08-05
5G消息工作组联合华为等7家单位 成立5G消息联合实验室
手机与无线通信
2021-08-05
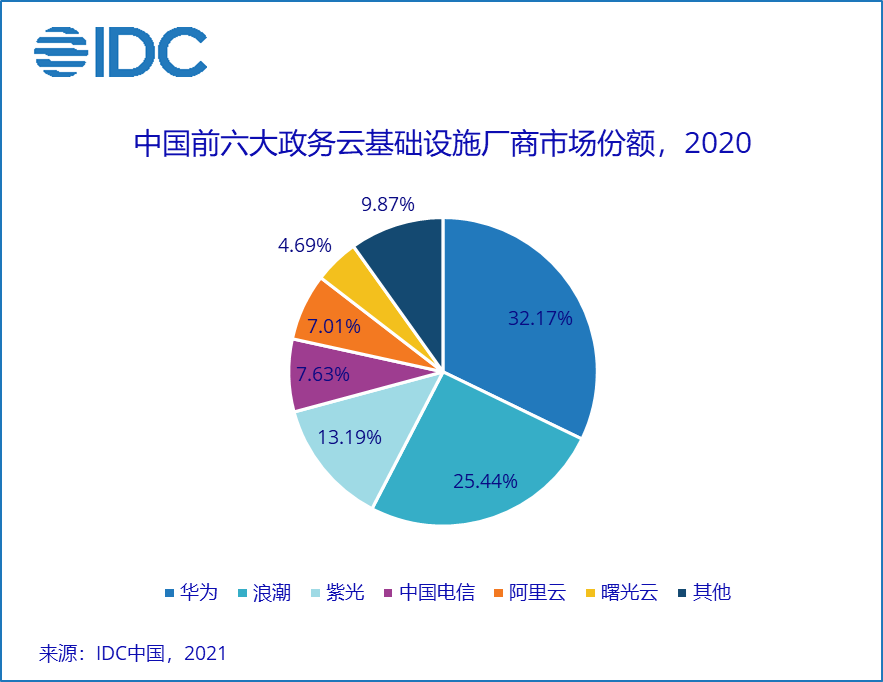
2020政务云基础设施市场研究报告发布——泾渭分明
智能计算
2021-08-05
荣耀MagicBook 14/15锐龙版2021款怎么样?收获媒体用户一致好评
消费电子
2021-08-05
以臻智远:极智嘉(Geek+)跨越机器人产品到智能物流的鸿沟
工控自动化
2021-08-05
康普观点:构建合适的 Wi-Fi 6 基础设施至关重要
手机与无线通信
2021-08-05
新一代蓝牙音频LE Audio,助力小米提升音频体验标准
手机与无线通信
2021-08-05
点击查看更多
电子设计方案
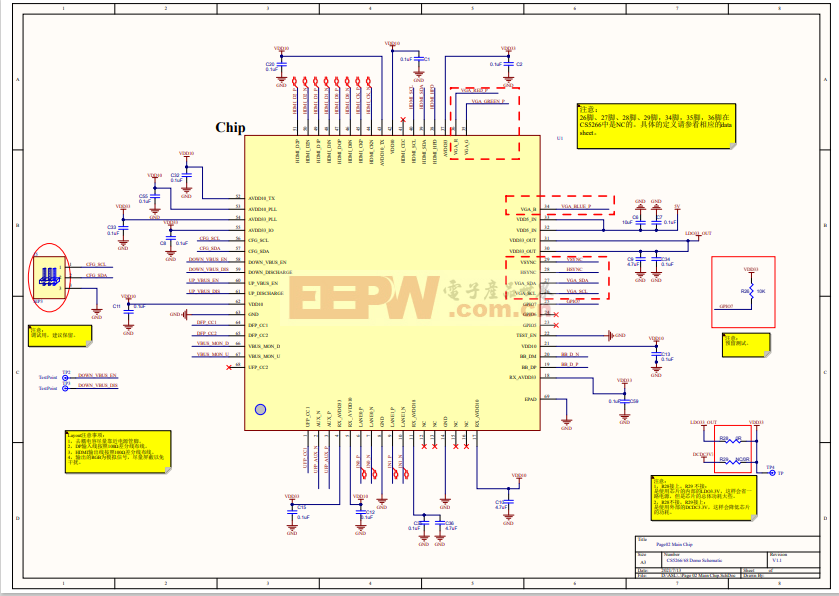
CS5268电路设计|TYPEC转HDMI/VGA/PD/U3扩展坞电路
2021-07-26
CS5268电路
扩展坞电路
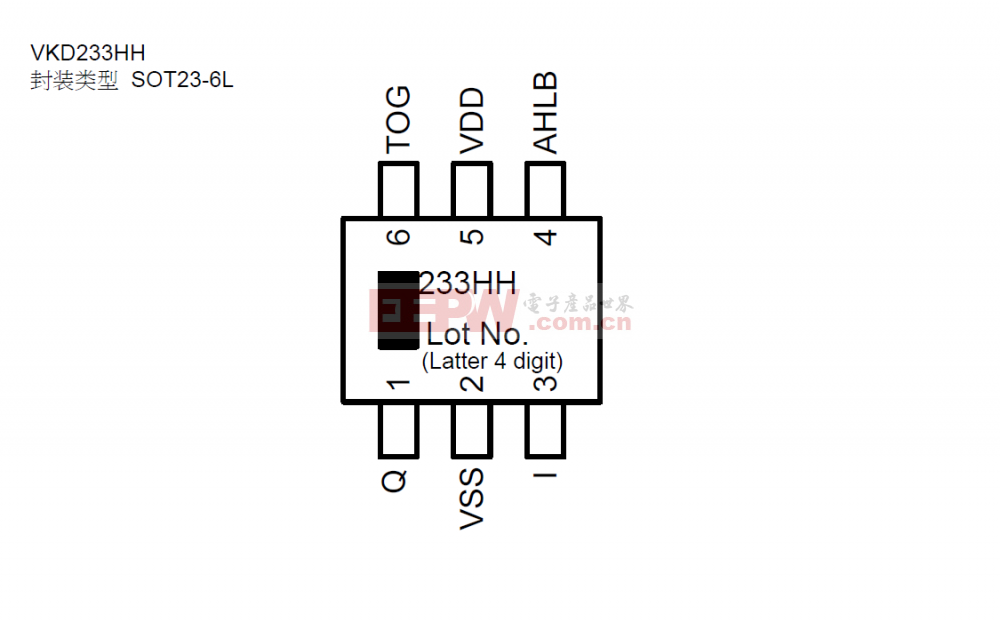
触摸检测芯片VKD233HH稳压电路电路图参考
2021-07-26
单按键触摸芯片
触摸耳机芯片
检测蓝牙耳机芯片
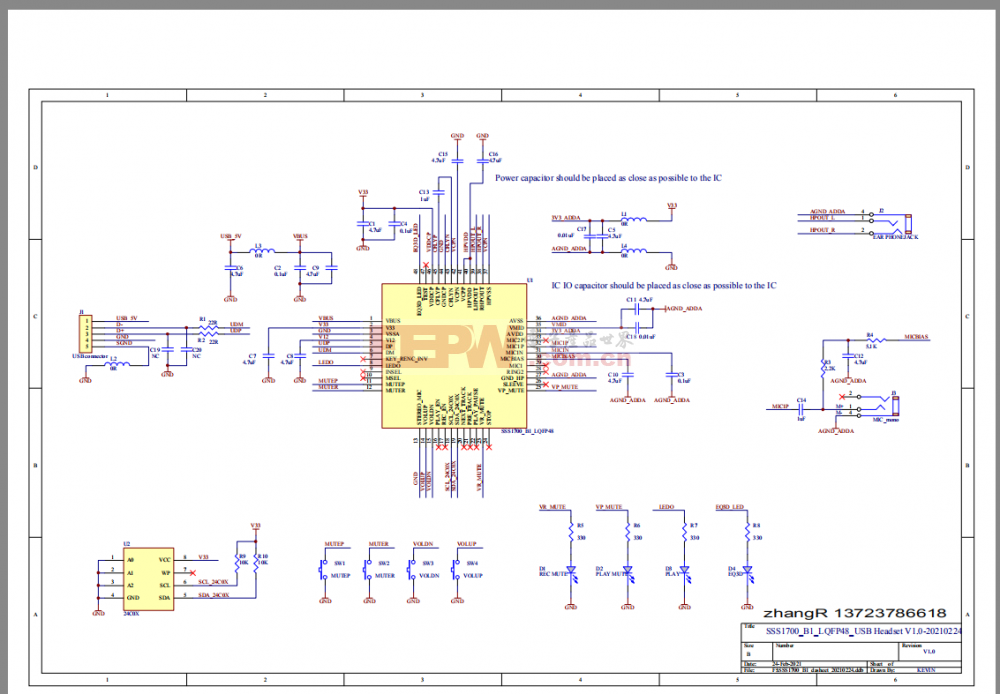
SSS1700设计电路参考|USB耳机麦克风方案参考电路
2021-07-26
SSS1700
SSS鑫创代理商
USB音频方案
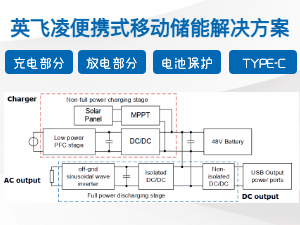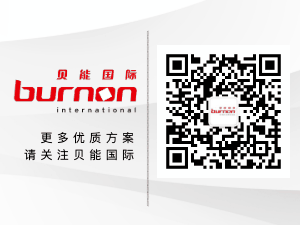
英飞凌便携式移动储能解决方案
2021-06-30
英飞凌
贝能
移动储能
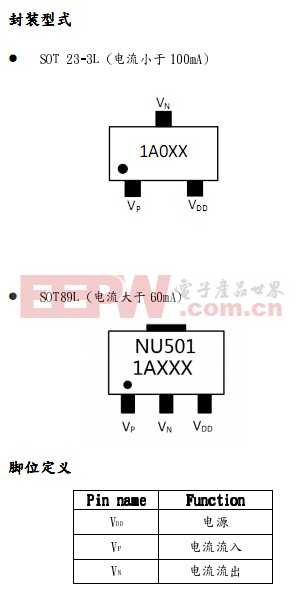
一款LED灯双色温调光驱动ICNU501/1A040/1A020/1A060电路控制
2021-05-10
NU501应 LED灯带双色温调光
线性定电流恒流芯片NU
点击查看更多
白皮书
可配置且简单易用的组合式可靠性检查
上传时间:2021-03-31
文件类型: PDF
文件大小: 1280.95K
MENTOR、AMD 和 MICROSOFT 合作开展云上 EDA
上传时间:2021-03-31
文件类型: PDF
文件大小: 571.97K
颠覆性的半导体测试方法
上传时间:2021-02-03
文件类型: PDF
文件大小: 10589.92K
CMP 建模的机器学习方法
上传时间:2021-01-20
文件类型: PDF
文件大小: 1902.86K
树莓派杂志《The MagPi》第101期(英语原版)
上传时间:2021-01-11
文件类型: PDF
文件大小: 32791.44K
NI硬件在环(HIL)合集:测试赋能创新
上传时间:2020-10-19
文件类型: PDF
文件大小: 1618.54K
提高早期设计周期的 LVS 验证效率
上传时间:2020-09-15
文件类型: PDF
文件大小: 944.96K
Bourns 白皮書下載 -高压储能应用解決方案
上传时间:2020-09-02
文件类型: PDF
文件大小: 2556.59K
利用 Calibre nmLVS-Recon 技术加快上市速度:电路验证新范式
上传时间:2020-08-24
文件类型: PDF
文件大小: 971.38K
并非所有硬件加速器的设计思路都是一样的
上传时间:2020-08-24
文件类型: PDF
文件大小: 1240.85K
点击查看更多