
谷歌优化升级网络架构,打造生成式 AI 推理与训练高效利器
谷歌一位网络领域专家晋升至核心管理层、执掌这家搜索引擎、广告巨头(如今更是 AI 巨头)的基础设施研发业务,这绝非偶然。尤其关键的是,谷歌几乎已经落地了解耦式数据中心基础设施架构 —— 过去十余年间,我们一直在持续探讨、追踪这一技术方向。
在解耦、可组合的数据中心架构体系中,网络始终处于核心枢纽位置。企业不仅需要对网络进行性能调优,更要针对性定制专用网络,使其高度适配特定业务负载,这也是差异化网络架构诞生的核心原因。
传统一体化服务器被拆解为独立硬件单元,以机架模块化方式部署,算力、内存、I/O、加速卡、存储资源可自由组合,灵活构建不同规格的虚拟集群:小集群承载轻量化分布式任务,超大规模集群专注单一巨型 AI 作业。这套复杂架构,绝非仅靠在机架内堆叠 PCIe 交换芯片就能实现。
从传统分布式计算、存储系统,到跨区域、全球化数据中心互联,专用网络与通信协议正迎来全面普及。谷歌自研网络技术布局已久:2019 年,谷歌公开基于 Linux 自研的网络操作系统Snap,以及配套数据面引擎 Pony Express,该套方案早在 2016 年便已投入量产部署。
四年前,谷歌推出Aquila协议,可为小规模紧耦合集群提供媲美 InfiniBand 的超低时延能力;同步配套研发机架顶置网卡芯片 TiN,基于蜻蜓全互联拓扑,实现千节点集群的定制化组网。此外,谷歌与英特尔联合为 “芒特埃文斯” DPU 打造Falcon低时延网络传输接口,进一步丰富低延迟算力互联方案。
上周谷歌正式发布TPU 8系列芯片,面向推理场景的 TPU 8i 与面向训练场景的 TPU 8t 同步亮相。本文将深度解析两大核心技术:一是谷歌自研的Boardfly 芯片间互联(ICI) 全新拓扑,用于 TPU 算力集群组网,并实现跨芯片一定程度的内存一致性;二是全新室女座(Virgo) 横向扩展级以太网架构,面向全域数据中心规模部署,全面适配 TPU 集群及各类服务器机架互联。
此前历代 TPU 集群均采用环形拓扑组网:中小规模集群使用二维环网,搭载数千颗 TPU 的超大规模计算集群则升级为三维环网。
环形拓扑具备多维度互联特性,广泛应用于超级计算机架构:IBM 蓝色基因大型并行超算、富士通研发的 “K 超算” 与 “富岳超算” 搭载的六维 Tofu 互联架构,均是典型案例。
环形拓扑适合海量硬件节点组网,但横向扩容难度极高。二维环网最大仅支持 256 颗加速卡互联;谷歌上一代铁木 TPU v7e 采用的三维环网,上限为 9216 颗加速卡;而全新太阳鱼 TPU 8t 训练集群,依托升级版三维环网,将单系统镜像互联规模提升至 9600 颗 TPU。
环形拓扑适配分布式并行计算,但设备间数据转发跳数过多,会显著增加传输时延,该特性勉强满足大模型训练需求,却完全无法适配推理业务。推理场景的核心目标是极致降本,且存在大量全规约、全互联通信需求,当前主流混合专家(MoE)大模型尤为依赖高频低延迟互联。
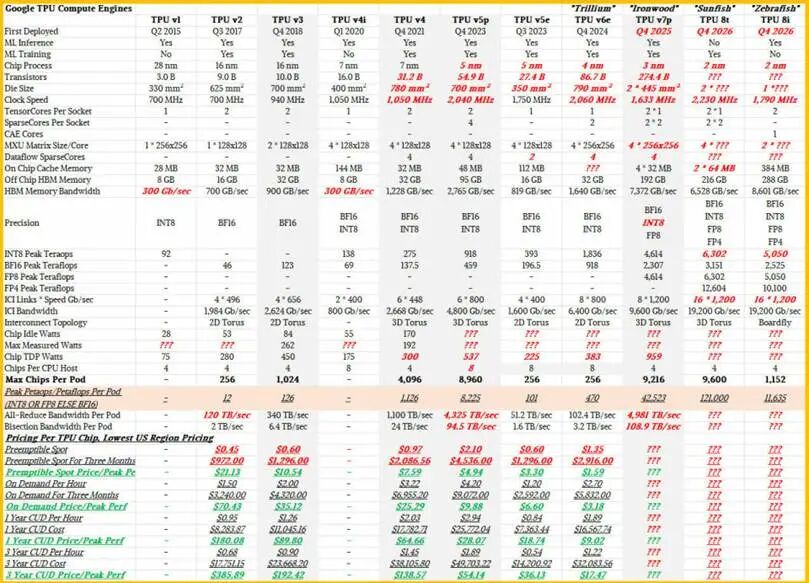
为此,谷歌为斑马鱼 TPU 8i 推理芯片量身打造Boardfly 全新拓扑架构。该架构单集群可实现 1152 颗 TPU 8i 一体化内存与算力协同组网;同等规模下,网络转发跳数从三维环网的 16 跳压缩至 7 跳。
Boardfly 拓扑借鉴近十五年超算领域普及的蜻蜓拓扑设计,推理集群网络直径降低 56%,大幅削减数据传输尾延迟。谷歌实测数据显示,在推理负载下,Boardfly 架构的数据传输平均时延,较三维环网直接降低 50%。
时延优化能够充分释放 TPU 8i 内置的集合通信加速引擎(CAE) 卸载芯片性能,保障硬件算力持续满载输出。更强的原生算力、扁平化Boardfly 互联架构与专用 CAE 加速单元形成协同,让全新推理集群的整体吞吐性能,较上一代铁木平台实现三倍及以上跃升。
下面是另一个

在 Boardfly 架构中,单块斑马鱼系统板搭载 8 颗 TPU 8i,通过芯片间互联端口实现板内全互联;每颗芯片预留冗余互联端口,可将 8 块系统板进一步级联,构建机架级 32 颗 TPU 全互联体系,机架内任意两颗芯片仅需 1~2 跳即可完成通信,且全程采用低成本铜缆互联。
如需扩展至 1152 颗 TPU、合计 36 组算力单元的超大规模推理集群,谷歌接入阿波罗(Apollo) 光电路交换设备(隶属木星数据中心骨干网络),实现跨集群高速互联。
这套「芯片间互联 + 光电路交换」组合架构,是跳数大幅压缩的关键:光交换设备搭载海量光口,推理系统板可集成更多光收发模块,大幅提升板间光纤互联密度。对比上一代三维环网,32 节点集群的光电互联链路数量提升约 4~8 倍,硬件互联瓶颈彻底解除。

面向 AI 训练的规模化组网升级
AI 训练与推理的负载需求截然不同,谷歌会尽可能减少光电路交换设备的使用 —— 相较于博通、思科、英伟达 ASIC 架构的以太网交换机,光交换硬件成本更高、供给更稀缺。
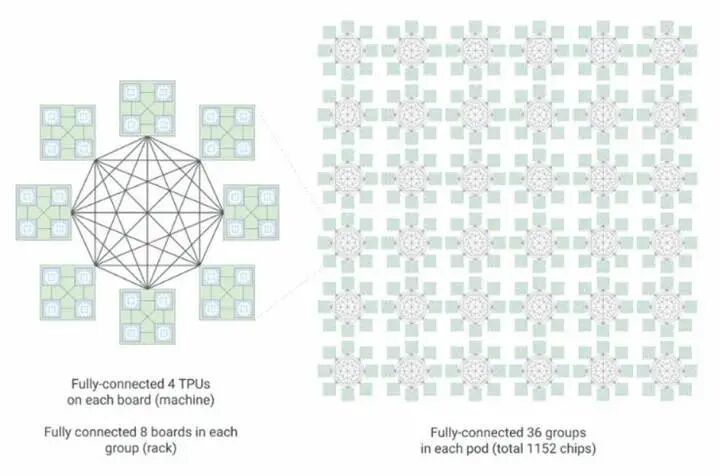
谷歌并未完整披露室女座(Virgo)横向扩展网络的底层硬件参数,但明确了核心设计思路:不再单纯追求单端口超高速率,而是平衡带宽需求、高基数端口密度与扁平化网络架构,通过减少转发跳数控制整体部署成本。
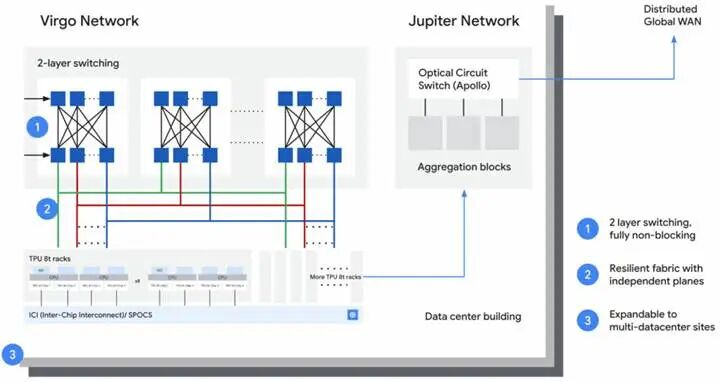
技术层面,Virgo 架构为 GPU、TPU 等加速卡机架,构建扁平化、无阻塞双层全域互联拓扑。阿波罗光交换设备不再用于训练集群横向扩容,仅负责对接谷歌数据中心内通用算力、存储资源池。
官方数据显示,单套 Virgo 网络架构可无缝互联多达 13.4 万颗 TPU 8t 芯片,提供 47PB/s 无阻塞二分带宽;太阳鱼 TPU 8t 单芯片横向扩展带宽达 400Gb/s,是上一代铁木 v7e 100Gb/s 端口带宽的四倍,网络架构时延同步降低 40%。
谷歌超大规格 TPU 训练集群的构建逻辑清晰:单集群内,依托三维环网芯片间互联,最高可容纳 9600 颗 TPU 8t 算力芯片;结合深度优化 RDMA 协议、借鉴 Aquila 协议与 TiN 混合交换网卡技术的 Virgo 数据中心网络,再叠加 JAX、Pathways 两大 AI 框架专属优化,单套 Virgo 组网可支撑 13.4 万颗TPU 协同训练。
多套 Virgo 架构通过光电路交换设备级联后,可组建百万级 TPU超大型逻辑训练集群,满足万亿参数大模型、通用人工智能的极限训练需求。
除此之外,谷歌为 TPU 8t 新增原生 RDMA 支持,推出两大关键技术:TPU 直连 RDMA与TPU 直连存储。两项技术对标英伟达 GPU 生态成熟方案,补齐了 TPU 长期缺失的高速互联能力。
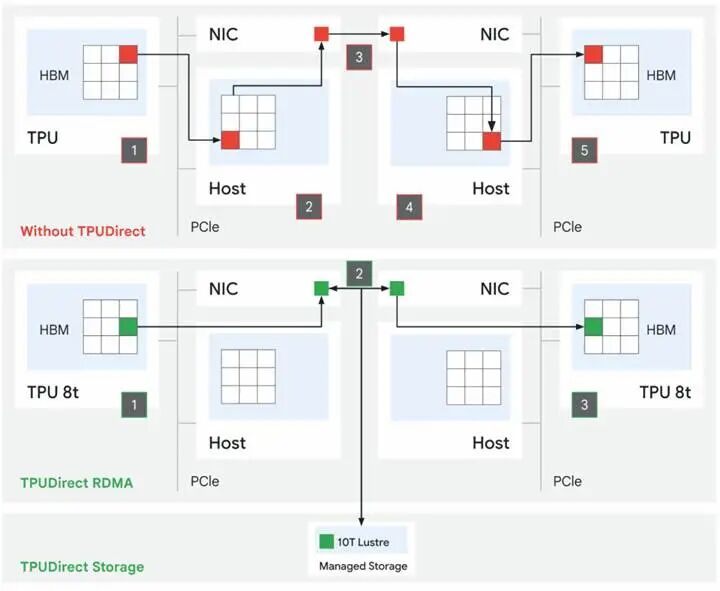
实测结果显示,在谷歌托管级 Lustre 10T 存储服务中,TPU 直连存储技术可将存储访问性能提升 10 倍,彻底解决上一代 TPU 平台存储 IO 瓶颈。而TPU 内存 RDMA 互联的具体性能提升幅度,谷歌暂未公开细节。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码